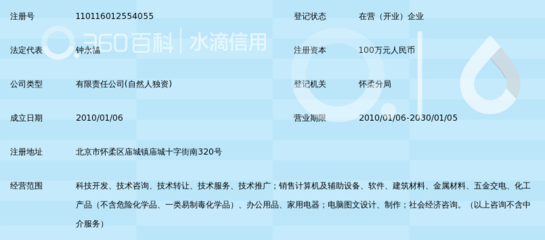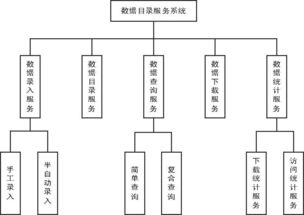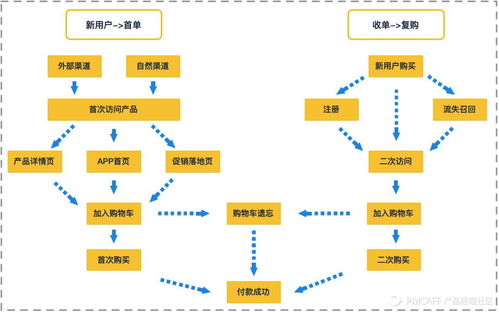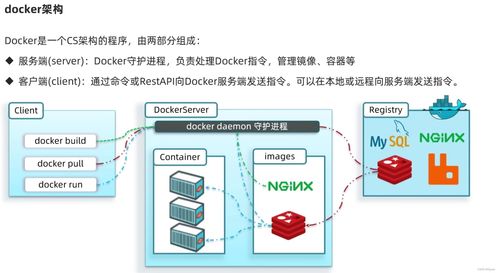
在2016年,由麻省理工學院《技術評論》評選出的“十大突破技術”中,深度語音識別系統(Deep Speech Recognition)赫然在列,標志著人工智能在感知智能領域邁出了關鍵一步。這項技術不僅徹底改變了人機交互的方式,也為全球科技產業,包括北京的計算機系統服務業,帶來了深遠的影響和新的發展機遇。
深度語音識別:2016年的技術里程碑
2016年,基于深度神經網絡(DNN)的語音識別技術取得了質的飛躍。與傳統方法相比,深度語音識別系統能夠通過多層神經網絡模型,直接從原始音頻數據中學習并提取復雜的特征,極大地提升了在嘈雜環境下的識別準確率和魯棒性。以百度Deep Speech 2等系統為代表,其識別錯誤率接近甚至超越了人類水平,實現了從“能聽清”到“能聽懂”的跨越。這項突破使得語音接口變得真正實用,為智能助手、實時翻譯、車載系統、智能家居等應用鋪平了道路,被視作開啟自然交互時代的核心技術之一。
技術核心與產業賦能
深度語音識別系統的核心優勢在于其端到端的學習能力。它避免了傳統流水線式中繁瑣的聲學特征手工設計和音素建模,通過海量數據訓練,使系統能夠理解上下文、適應不同口音和語速。2016年,該技術的成熟得益于三大要素:更強大的計算能力(尤其是GPU的廣泛應用)、大規模標注語音數據的積累以及深度學習算法(如循環神經網絡RNN、長短時記憶網絡LSTM)的持續優化。
這一突破迅速從實驗室走向產業,催生了一個龐大的應用生態。它不僅是消費級產品(如智能手機語音助手)的標配,更深入到了客服、醫療聽寫、教育、司法筆錄等專業領域,提升了效率并創造了新的服務模式。
北京計算機系統服務的響應與變革
作為中國的科技創新中心,北京的計算機系統服務產業敏銳地捕捉到了這一技術浪潮帶來的機遇。2016年前后,北京的產業生態呈現出以下積極變化:
- 技術集成與解決方案升級:眾多北京的軟件與信息技術服務企業,開始將先進的深度語音識別API(如來自百度、科大訊飛等公司的開放平臺)集成到自身的解決方案中。無論是為企業客戶定制智能客服系統,還是開發面向特定行業的語音分析工具,深度語音識別都成為了提升產品競爭力的關鍵模塊。
- 驅動云計算與大數據服務需求:深度語音識別模型的訓練和部署需要強大的算力和存儲支持。這直接刺激了北京地區云計算服務提供商(如阿里云、騰訊云在北京的數據中心)的業務增長。企業無需自建昂貴的計算集群,即可通過云服務獲取語音識別能力,這降低了創新門檻,促進了中小企業的技術應用。
- 催生新業態與專業化服務:圍繞語音技術,北京涌現出一批專注于語音交互設計、語義理解、垂直領域語音數據庫構建的專業服務公司。計算機系統服務不再局限于傳統的軟硬件支持和運維,而是向提供“AI能力即服務”的更高價值環節延伸。
- 人才培養與創新研發集聚:依托中關村等科技園區以及清華大學、北京大學等高校的研究實力,北京吸引了大量人工智能人才,聚焦語音技術的前沿研發。這種產學研的緊密互動,確保了北京計算機系統服務業能持續獲得技術滋養,保持領先地位。
展望:持續演進與未來影響
自2016年成為突破技術以來,深度語音識別已進一步與自然語言處理(NLP)融合,走向了更全面的“語音語言智能”。對于北京計算機系統服務而言,這意味著機會的持續擴大:從簡單的語音轉文字,到語音情感分析、內容理解、智能決策支持,技術鏈條的延長將帶來更廣闊的服務空間和增值潛力。
2016年深度語音識別系統的突破,不僅是一項孤立的技術成就,更是推動整個信息產業,特別是如北京這樣的高端服務業集群,向智能化、人性化方向轉型的重要催化劑。它證明了前沿基礎研究能夠快速轉化為實際生產力,并重塑區域產業競爭力的格局。